Availability is one of the five SOC 2 Trust Services Criteria, but it is not required in every audit. Security is the only mandatory criterion. Organizations add Availability when they need to show that systems are available for operation and use as committed or agreed, especially when uptime and access commitments appear in contracts or service-level agreements. The practical implication is straightforward. For many teams pursuing SOC 2, Availability is not the default choice. It is a scope decision tied to customer expectations, operational maturity, and the ability to prove reliability with evidence.
That’s the counterintuitive part of soc 2 availability criteria explained. Many teams assume Availability should automatically be included because uptime matters to every software company. In practice, it only belongs in scope when the business case is clear. The strongest reason is usually not internal preference. It’s whether customers depend on continuous access and whether procurement or security reviews are asking you to prove it.
What are the SOC 2 Availability Criteria
The SOC 2 framework includes security, availability, processing integrity, confidentiality, and privacy. But security is the only mandatory criterion required in every SOC 2 examination. Availability is optional, and organizations choose it based on whether system availability is critical to clients and whether clients explicitly request it during vendor evaluation, as explained by the Cloud Security Alliance overview of the five SOC 2 Trust Services Criteria.
That optional status matters because Availability adds work. It expands the story your audit report must tell. If you include it, you’re no longer proving only that your environment is protected. You’re also proving that the system stays operational and accessible in line with commitments you’ve made to customers.
Why Availability matters in a SOC 2 audit
Availability is often best understood through the promises your company already makes. If your contracts, order forms, or SLAs commit you to uptime, incident handling, or continuity expectations, Availability gives customers assurance that those promises aren’t just marketing language.
For someone pursuing SOC 2, this matters for three reasons:
- Customer trust: Enterprise buyers often want evidence that your service won’t disappear during a critical workflow.
- Contract alignment: If legal and sales teams promise access commitments, audit scope should reflect that reality.
- Scope discipline: If customers don’t care about Availability, adding it too early can create avoidable compliance overhead.
A helpful primer on the broader framework is What Is SOC Compliance, especially if your team is still deciding how SOC reporting maps to sales, security, and procurement.
What auditors look at
Availability is assessed through the framework’s Availability points of focus. The verified guidance describes three core areas auditors evaluate: Availability Management (A1), Performance Monitoring (A2), and Incident Management (A3).
Practical rule: Add Availability when downtime would affect customer operations or when buyers are already asking for proof of uptime controls.
If you can’t tie the criterion to a real customer need, a security-only report is often the better first step. If you can, Availability becomes less of an optional extra and more of a commercial requirement.
The Core Components of Availability
Availability sounds narrow, but in audits it touches architecture, operations, and documentation. The criterion becomes manageable when you group it into the operating areas teams already own.
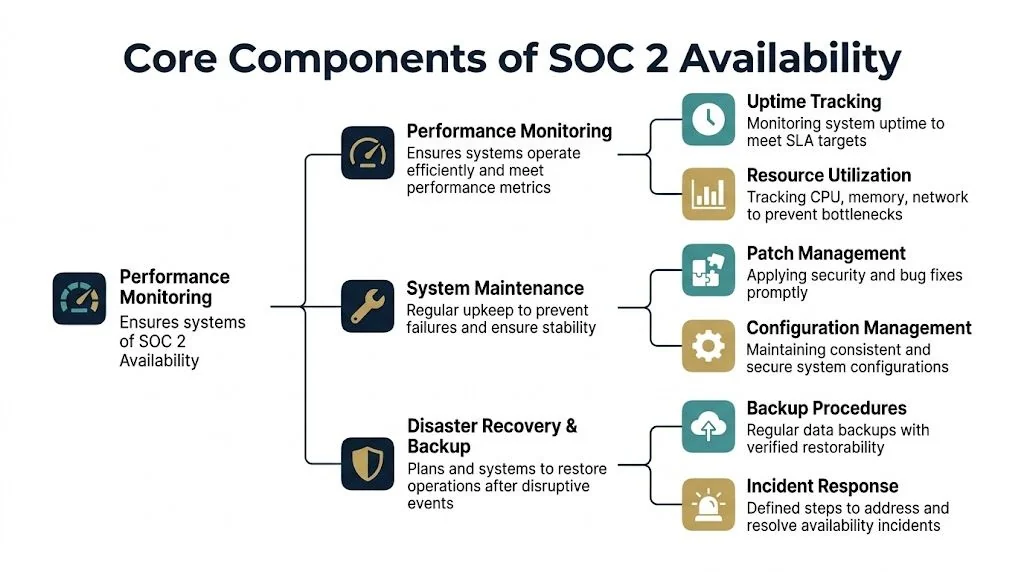
Capacity and performance management
The first pillar is making sure systems can handle expected demand. Auditors care because many outages are not mysterious failures. They’re predictable capacity problems that nobody tracked early enough.
In practice, that means watching infrastructure and application behavior before customers feel the impact. Teams usually rely on platforms such as Datadog, New Relic, Grafana, Amazon CloudWatch, or Azure Monitor to track resource saturation and service degradation. What matters is not the brand of tool. It’s whether the monitoring supports timely action and whether the thresholds, alerts, and ownership are documented.
Backup and restoration
A backup policy isn’t an Availability control if nobody verifies restore capability. Auditors look for evidence that data can be recovered and that the process is repeatable under pressure.
Good backup design usually includes these habits:
- Defined scope: Critical systems, supporting data stores, and configuration assets are included.
- Restore testing: Teams validate that backups can be used.
- Ownership: Someone is accountable for failed jobs, exceptions, and retention alignment.
Availability gets stronger when backup evidence shows operational discipline, not just a screenshot from a storage console.
Disaster recovery and incident response
The final pillar is recovering from disruption. That includes planning, response coordination, and restoring service in a controlled way. If your company offers a service that customers rely on throughout the day, this area often carries the most business weight.
The controls here usually include documented disaster recovery procedures, escalation paths, communication rules, and decision-making authority during an outage. Mature teams also connect this work to incident management so engineering, support, and leadership don’t improvise in the middle of an availability event.
For SOC 2, this matters because Availability isn’t about claiming perfection. It’s about showing that you’ve built a credible operating model for staying up, detecting issues, and recovering when systems fail.
Mapping Availability Controls to Your Systems
The Availability criterion becomes real when you map it to the systems your customers use. The verified guidance identifies four specific control areas: capacity monitoring and management (A1.1), infrastructure performance assessment, business continuity planning, and disaster recovery procedures. It also states that A1.1 requires organizations to “maintain, monitor, and evaluate current processing capacity and use of system components…to manage capacity demand” across servers, networks, applications, and cloud resources, with auditors expecting documented capacity plans and performance metrics, according to this breakdown of SOC 2 Availability control areas.
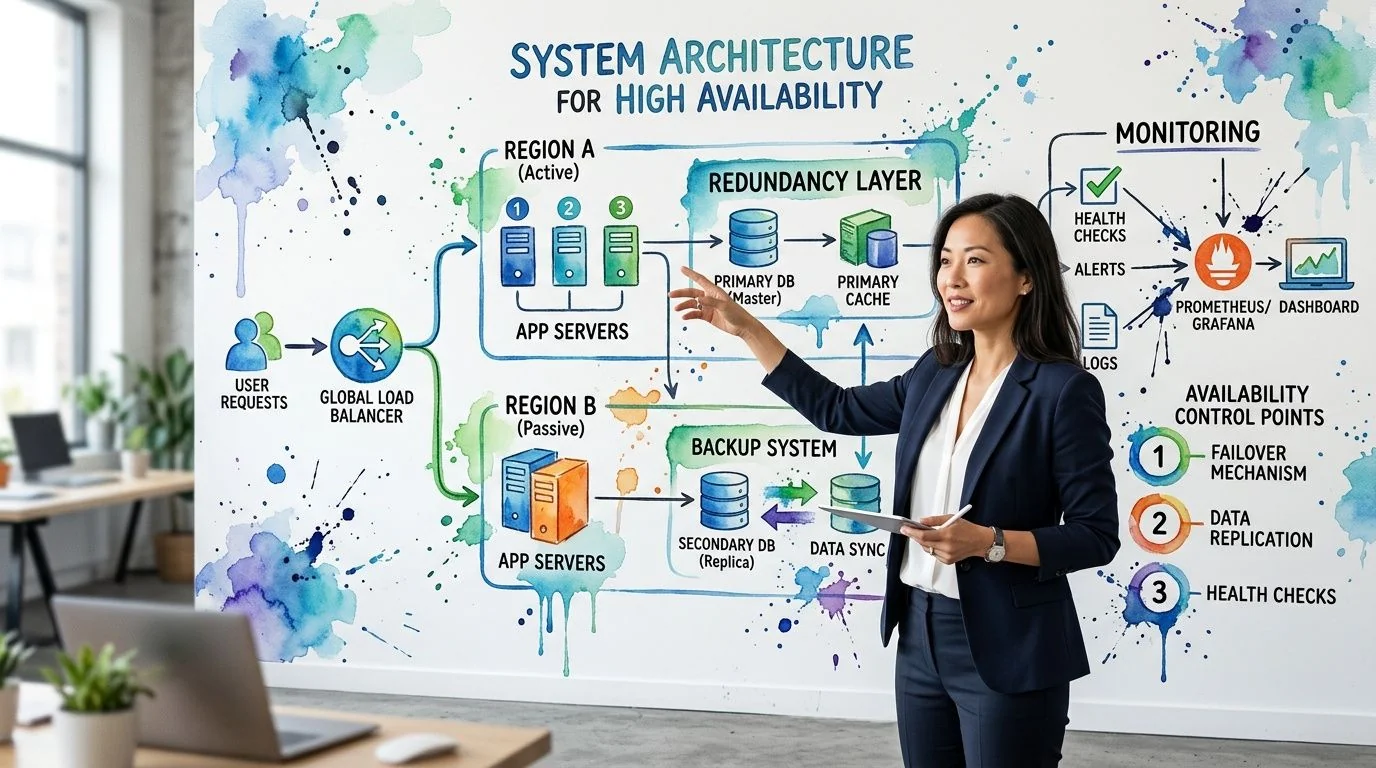
Start with the user-facing path
Map controls to the full service path, not just your cloud account. For a SaaS company, that usually includes the application tier, databases, queues, third-party dependencies, identity services, observability stack, and support workflows. If a failure in any one of those areas can break customer access, it belongs in your Availability narrative.
A practical system map often includes:
- Ingress and application layers: Load balancers, web services, API gateways, and front-end hosting
- Stateful components: Databases, object storage, cache layers, and message brokers
- Dependencies: Payment providers, email delivery, identity providers, and cloud-native managed services
- Operational tooling: Logging, alerting, paging, status communication, and ticketing
Teams using AWS can see how this thinking carries into shared responsibility and control design in this guide to AWS SOC 2 compliance.
Build controls around failure modes
Don’t write controls at the level of “monitor the environment.” Write them around known failure patterns. That gives auditors a clear line between risk, control, and evidence.
Examples that usually work well:
| System area | Failure mode | Practical control |
|---|---|---|
| Database | Storage or compute saturation | Capacity review, alerting, scaling plan, documented owner |
| API tier | Error spikes or latency growth | Application monitoring, paging, on-call runbook |
| Backup platform | Failed backup jobs | Daily job review, exception ticketing, restore validation |
| Core service region | Regional disruption | DR plan, failover procedure, tested recovery workflow |
Document the operating model
Availability controls fail audits less often because the technology is weak and more often because the operation is undocumented. Auditors want to see who reviews metrics, how incidents escalate, what triggers action, and how exceptions are handled.
Many teams borrow structure from broader security frameworks when documenting these controls. If you need a crosswalk for governance and resilience practices, the NIST SP 800-53 guidelines are useful for framing policy ownership, contingency planning, and monitoring discipline.
A short technical walkthrough can also help align engineering and compliance teams before evidence collection starts.
The companies that handle Availability well usually do one thing consistently. They connect system design to repeatable human action. Monitoring, continuity, and recovery only satisfy an auditor when someone can show how those processes operate in practice.
Sample Controls and Evidence for Your Audit
Availability audits get easier when you think like an auditor. The question isn’t whether a control exists in theory. The question is whether you can produce evidence that it operated as designed during the review period.
That difference matters. Teams often have solid technical practices but weak audit evidence because ownership is scattered across engineering, SRE, and support. The fix is to define evidence sources before fieldwork starts.
What good evidence looks like
Auditors usually want a mix of policy, configuration, operational records, and proof of execution. A clean screenshot alone rarely carries enough weight. It helps when paired with logs, tickets, meeting notes, approval records, post-incident reviews, or test outputs.
If your availability program overlaps heavily with resilience planning, this guide to SOC 2 business continuity controls is a useful companion because it addresses the operational side that often supports Availability evidence.
Sample Availability Controls and Evidence Requirements
| Control Objective | Sample Control | Required Evidence | Common Gap |
|---|---|---|---|
| Detect capacity strain before service impact | Engineering reviews infrastructure and application capacity on a defined cadence and tracks exceptions | Capacity management policy, monitoring dashboards, review records, tickets for remediation, growth or scaling plan | Monitoring exists but no documented review or follow-up action |
| Identify performance degradation quickly | Alerting is configured for key services and routed to on-call responders | Alert configuration, on-call schedule, alert test record, incident tickets showing response workflow | Alerts are noisy, disabled, or not tied to ownership |
| Protect recoverability of production data | Backups run on schedule and failed jobs are investigated | Backup policy, job logs, exception tickets, retention settings, restore test output | Teams collect backup success logs but never test restores |
| Support continuity during disruption | Business continuity procedures define roles, communications, and manual workarounds | Continuity plan, role assignments, tabletop exercise notes, action items from last test | Plan exists in a document repository but staff haven’t exercised it |
| Restore service after major outage | Disaster recovery procedures define recovery steps and decision authority | DR plan, test results, post-mortem, evidence of updates after lessons learned | Recovery plan is outdated or limited to a generic checklist |
| Manage downtime incidents consistently | Incidents are tracked, escalated, and reviewed after resolution | Incident management procedure, ticket records, timelines, root cause analyses, corrective actions | Teams resolve incidents in chat without preserving a formal record |
| Reduce outage risk from changes | Production changes follow review, testing, and rollback practices | Change tickets, approvals, deployment logs, rollback plan, emergency change documentation | Emergency changes bypass process and never get retrospective review |
Strong Availability evidence usually answers four questions at once: what was supposed to happen, who owned it, what actually happened, and how the team handled exceptions.
This is why evidence planning should start before the audit window. If it starts during fieldwork, the work becomes a reconstruction exercise, and reconstruction is where avoidable findings appear.
Common Availability Gaps and How to Remediate Them
Most Availability findings come from operating shortcuts that made sense at an earlier stage. A startup can survive with tribal knowledge, manual checks, and a loosely defined recovery plan for a while. It can’t defend those habits well in a SOC 2 audit.

The untested plan
The most common weakness is the document that nobody has exercised. Companies write a disaster recovery plan, store it in Notion or Confluence, and assume that’s enough. It isn’t.
Remediation usually looks like this:
- Run a tabletop exercise: Walk through a realistic outage and record decisions, blockers, and owners.
- Test one recovery scenario: Start with a non-critical service if a full failover is too risky.
- Update the plan afterward: Capture what changed, who approved updates, and how teams were informed.
Monitoring blind spots
Many teams monitor infrastructure health but miss customer-impact signals. CPU and memory matter, but so do response times, error rates, queue backlogs, and failed third-party calls. If those aren’t visible, incidents surface through support tickets instead of alerting.
A useful benchmark is to ask whether your monitoring would explain a user-facing outage such as a 503 Service Unavailable Error. If the answer is no, your observability is probably too shallow for Availability scope.
If support tells you the system is down before monitoring does, your Availability controls aren’t mature enough yet.
Informal capacity planning
Early teams often scale reactively. That works until growth, customer concentration, or seasonal demand creates pressure on a small number of systems. Auditors will question whether capacity management is real if it depends on one engineer remembering to check dashboards.
Use a simple remediation checklist:
- Assign an owner: One team or role should own recurring capacity reviews.
- Define thresholds: Set clear criteria for investigation and escalation.
- Record actions: Keep tickets or meeting notes that show what decisions were made.
- Connect to roadmap planning: Expansion work should appear in normal engineering planning, not only in incident cleanup.
Availability matures when teams replace intuition with repeatable operating habits. That’s what auditors want to see, and it’s what customers rely on during real disruptions.
Costs Timelines and Auditor Selection for Availability
The hardest Availability question isn’t technical. It’s whether adding the criterion is worth it now.
The verified guidance highlights a real gap in the market: most content explains what Availability is, but not when a startup should pursue it instead of a security-only report. It also notes that the decision should be based on company stage, customer concentration, and incremental cost and timeline additions, while a full audit can range from 3 to 20 months according to Linford & Co’s discussion of Availability scope decisions.

When Availability usually makes sense
Availability is often a strong fit when your company has one or more of these conditions:
- Customer contracts include uptime commitments: Your audit scope should support what sales and legal already promise.
- The product is operationally critical: Downtime disrupts customer revenue, workflows, or regulated activity.
- Procurement asks for it: Buyers are explicitly evaluating your resilience posture, not just baseline security.
- A small set of customers carries outsized revenue risk: Availability assurance can matter more when concentration is high.
If none of those are true, security-only SOC 2 is often the better first move. It reduces scope, simplifies evidence collection, and gives the team time to mature operations before claiming more than it can comfortably prove.
What changes when you add it
Adding Availability usually affects three things. First, it broadens your control inventory. Second, it increases the amount of operational evidence you need from engineering and support teams. Third, it raises the bar for auditor conversations because you’ll need to explain not only design, but execution under disruption.
That can slow readiness if your current environment has any of these traits:
| Condition | Likely effect on Availability scope |
|---|---|
| Weak monitoring ownership | Evidence gaps and inconsistent alerts |
| Untested DR procedures | Extra remediation before fieldwork |
| Heavy reliance on third parties | More dependency analysis and contractual review |
| Rapid architecture change | Harder to keep documentation current |
How to choose an auditor
Not every SOC 2 auditor is equally strong on cloud-native Availability controls. Ask pointed questions before you sign.
Use this short screening list:
- Architecture familiarity: Can they evaluate managed services, multi-service dependencies, and modern incident workflows?
- Evidence expectations: Do they explain what they’ll want for monitoring, backup validation, and continuity testing?
- Operational realism: Will they distinguish between startup-stage maturity and true control weakness?
- Communication style: Can they give clear readiness feedback before formal testing begins?
A good Availability auditor should understand how your systems stay up, how they fail, and how your team proves recovery. If they can’t have that conversation fluently, the audit will be slower and less useful.
Conclusion Achieving Audit Readiness for Availability
Availability is optional in SOC 2, but it isn’t minor. Once you include it, you’re making a formal claim that your service remains accessible as committed and that you can prove the controls behind that claim. That has value when customers depend on uptime, when contracts include service commitments, or when enterprise deals require stronger assurance than security alone.
The teams that succeed with Availability don’t treat it as a documentation exercise. They build a working operating model. Monitoring has owners. Backup jobs are reviewed. Restores are tested. Continuity and recovery plans are exercised, then updated. Incident records show what happened and what changed afterward. That’s what creates a defensible audit trail.
If you’re deciding whether to add Availability, the right question isn’t “Shouldn’t every serious company include it?” The right question is “Can we show, with evidence, that our systems are available as promised and recover in a controlled way when they aren’t?” If the answer is yes, Availability can strengthen both buyer confidence and the credibility of your report. If the answer is not yet, narrow the scope and mature the operation first.
SOC 2 audit readiness depends on matching scope to reality. For companies that need Availability in scope, readiness means tested controls, documented ownership, and an auditor who knows how to evaluate resilience in modern SaaS environments. If you need help finding that fit, SOC2Auditors.org helps teams compare firms and choose an auditor with the right experience for their Availability requirements.